




































the reCAPTCHA program has been securing websites for years -- and along the way helping Google to digitize countless old books. (YouTube)
Con enthsba!
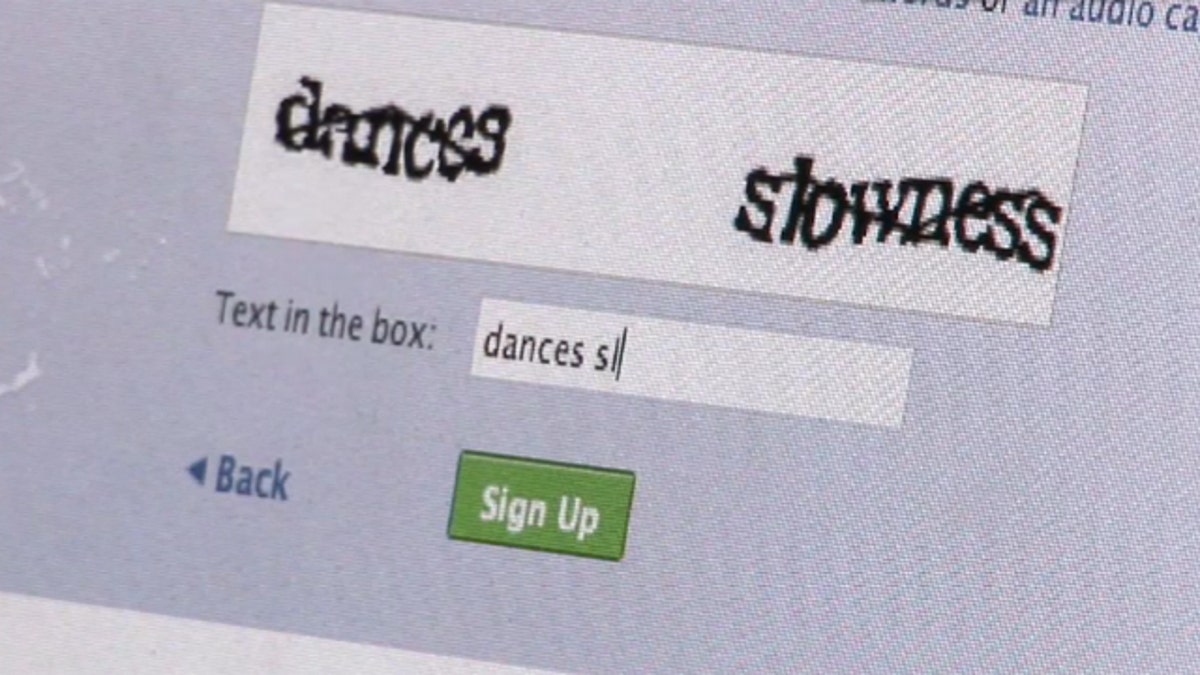
Look familiar? Those confusing semi-words you retype to buy Rolling Stones tickets on TicketMaster.com or sell an antique lamp on Craigslist might not read as real words, but they are. They're actually images from the pages of books -- and thanks to reCAPTCHA technology, they're a key reason Google has digitized more than 15 million books since 2004.
The Google Books project has vastly improved the quality of digitized text, thanks in part to those curvy, sometimes colorful words on the web that are filled out 200 million times a day, explained Carnegie Mellon University computer science professor Luis von Ahn, the inventor of the reCAPTCHA system.
“Humans, at least non-visually impaired humans, have no problem readings these distorted characters. But computer programs can’t do it as well yet,” von Ahn told FoxNews.com.
Google puts the obscure bits of books that it can't scan completely in the reCAPTCHA system and it’s up to humans rather than OCR machines to determine what the words really are. And by decoding the sometimes-fuzzy words that Google's optical character recognition (OCR) system is unsure about, you're helping the huge book project.
“Enthsba” may seem like Greek to you -- and it may actually be. Google says words from hundreds of countries and over 400 languages are part of the CAPTCHA program it acquired in 2009.
So congrats, Internet user! You're a part-time archivist.
But it hasn't always been so.
CAPTCHA (Completely Automated Public Turing Test to Tell Computers and Humans Apart) is a free program that von Ahn developed in 2000 to help Yahoo! with an e-mail spam problem.
“You type these distorted characters to prevent scalpers from writing up programs that can buy millions of tickets two at a time,” von Ahn said.
Two words appear in a CAPTCHA. The system knows the answer to one of the words and assumes the user typed in the other word correctly. The answer to the second word is then compared with what's written by other users and put into the pool of verified words.
“At first I was really proud of that.” But he told FoxNews.com that he started to feel bad for taking up Internet users’ time
He asked himself: “Can we do something useful at the same time?”
That’s when he came up with reCAPTCHA in 2007, which currently exists on over 100 websites including Facebook and Twitter
He took old issues of The New York Times and put them in the reCAPTCHA system. They digitized 20 years worth of editions, von Ahn reported. The system is clearly a success: Von Ahn did the math and figured out that 200 million CAPTCHA’s were filled out per day, taking about 10 seconds each.
Depending on the condition of words on the page, an individual set of characters may cycle through the reCAPTCHA system several times.
“When we’re not sure what a word is in the book, we do show it to a number of people,” Jimi Crawford, Google Books’ engineering director, told FoxNews.com.
Crawford said they have partnerships with over 40,000 publishers worldwide and reCAPTCHA is helping improve their mission of digitizing books.
“It makes such a huge difference in the reading experience on these books,” said Crawford because it improves the quality of works in ePublications.
The text from the scanned books appears the same in Google Books, of course: The images of the books created by the scanner aren't changing. But the unclear words are suddenly recognized in searches.
Books in the United States published prior to 1923 are under public domain and the copyright doesn’t exist, Crawford reported. Right now two million of those books are available for free downloads on Google Books.
More than 13 million newer books are also available, but depending on the publisher, only a percentage of the texts are free to read. Google has many older books waiting to be scanned, Crawford said, but right now the company is going in order of popularity.
So thanks for all your help, Web user!
Now get out there and qffundee ymxxowwo!